Rapid Failover
A serious video management system cannot exist without fault tolerance mechanisms. Luxriot EVO Global offers several redundancy features — database backup, management server mirroring, failover, fallback storage, replication, edge recording — which, by combined efforts, help to reduce disruption of the video recordings to zero by providing high availability service and keeping the recorded data integral.
In this article, we will take a closer look at failover mechanism for recording servers in the Luxriot EVO Global system and see how it can be fine-tuned to meet high standard requirements for redundancy, for instance, those dictated by Security Monitoring Standards from Monitoring & Control Centre (MCC) of UAE.
Briefly About Failover
The failover feature enables quick automated recovery of the recording system in case of a sudden failure. EVO Global server carefully tracks the operation of all the servers in the system by exchanging heartbeat messages with each one; if there is no response for too long, the central management server assumes that the target recording server is down and immediately replaces that server with a spare one.
What does actually happen when a faulty server is replaced? The central management server remembers the configuration of all the servers in the system; so, a secondary (spare) server is assigned a configuration that is identical to the one from the primary recording server. Thus, the fault has no consequences on everyone else in the system as all the live and recorded video streams are continuously available. When the malfunctioned machine comes back online, it is returned to operation either automatically or manually by the administrator, depending on the desired system configuration.
In order to achieve this, recording servers are split into groups — clusters — based on their location, purpose, importance, configuration and/or other attributes or their combinations. Inside the cluster, there may be any proportion of actual (primary) recording servers and 'spare parts' — failover nodes: thus, any required redundancy level can be reached. There are no limitations on the number of clusters or on the number of servers in a cluster.
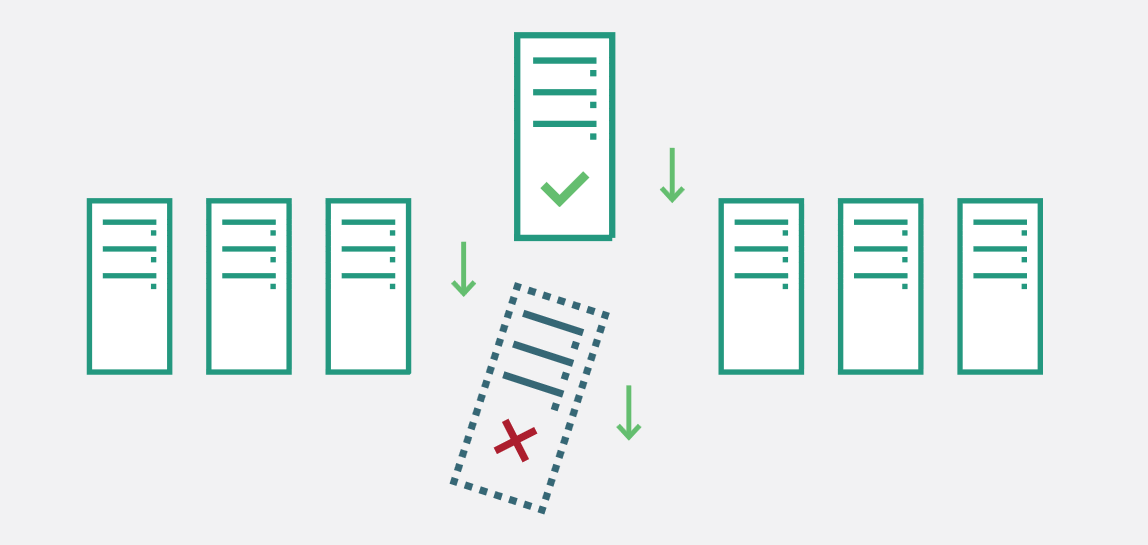
A faulty server is automatically replaced by a spare one thanks to the failover mechanism
There are several demands for the failover servers to ensure that a failover node can take over any server from the same cluster:
- failover nodes must be located in the same environment to be able to access all the devices,
- their hardware specifications must be equal or higher than the top spec recording server(s) from the same cluster (otherwise, review clusters and re-group servers),
- there must be no permanent device configuration assigned to any failover server — its configuration is to be empty while the failover node is idle.
For both primary recorders and failover servers, the same installation package — EVO Global Recording Server — is used, with server roles assigned later in their settings. The Global server itself does not participate in the failover clustering and is therefore not covered by failover. For this reason, we do not recommend using the Global server for recording (although it is allowed) but rather for management only. The central management server high availability is achieved using a different redundancy feature called central server mirroring.
Set Up Once and for All
Failover is configured via Luxriot EVO Console application. Generally, the plan is:
- Create a failover cluster
- Add all necessary recording servers to the EVO Global configuration — manually or using server autodiscovery
- Assign server roles (primary recorder or failover node) and define their settings
- Put the servers into the cluster(s)
The order of these steps is not crucial, e.g., you can first add the servers and create the failover cluster later.
We shall consider a system with one cluster that contains two primary recording servers and two spare servers. All these servers (four of them) are located in the same local network and, as a result, have access to the same cameras. This network can be different from the Global server network.
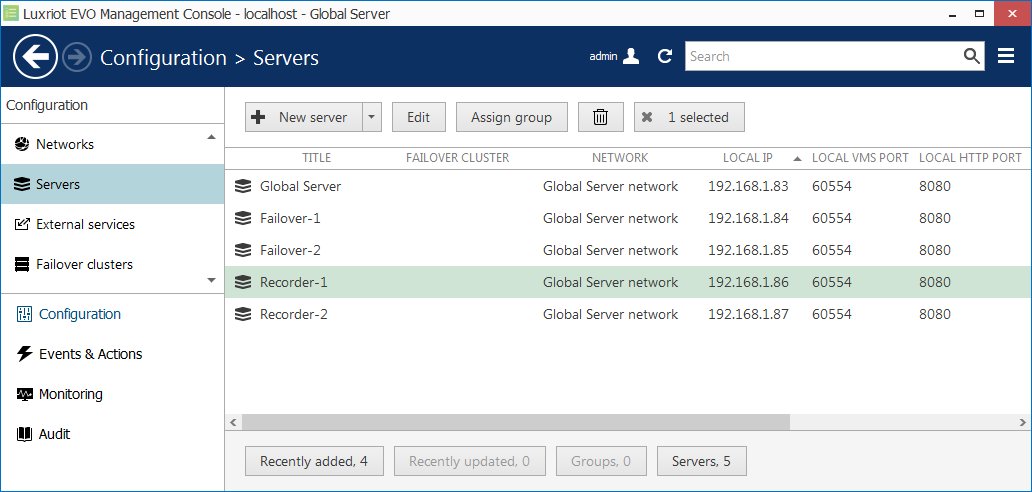
A list of servers ready to be added to a failover cluster
Setting Up Recording Servers
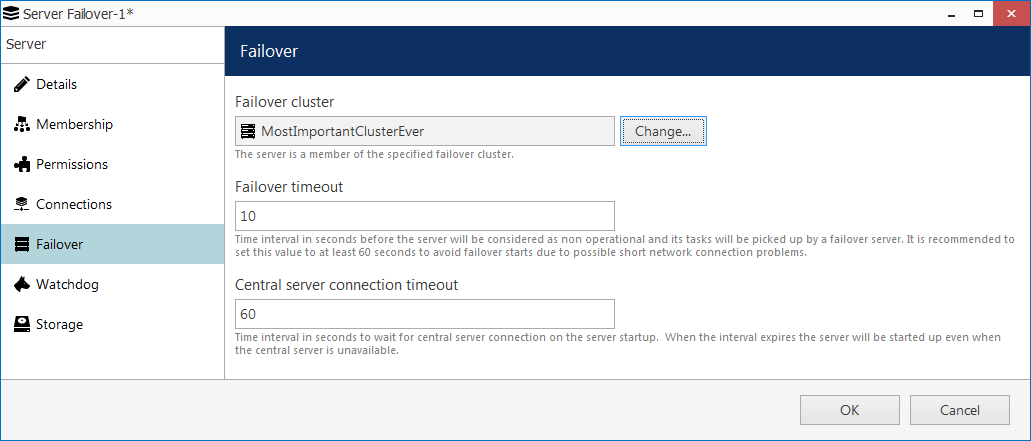
Double-click a recording server to bring up its properties editing dialog box, and switch to the Failover tab (do not forget to fill in the rest of the tabs afterward). Here, it is necessary to choose the failover cluster that servers will belong to, and define failover settings for this particular server.
Click Change to choose a pre-created failover cluster from the list. Do not worry if you have not created a cluster beforehand, you can do so right now by clicking the button in the bottom of the cluster list.
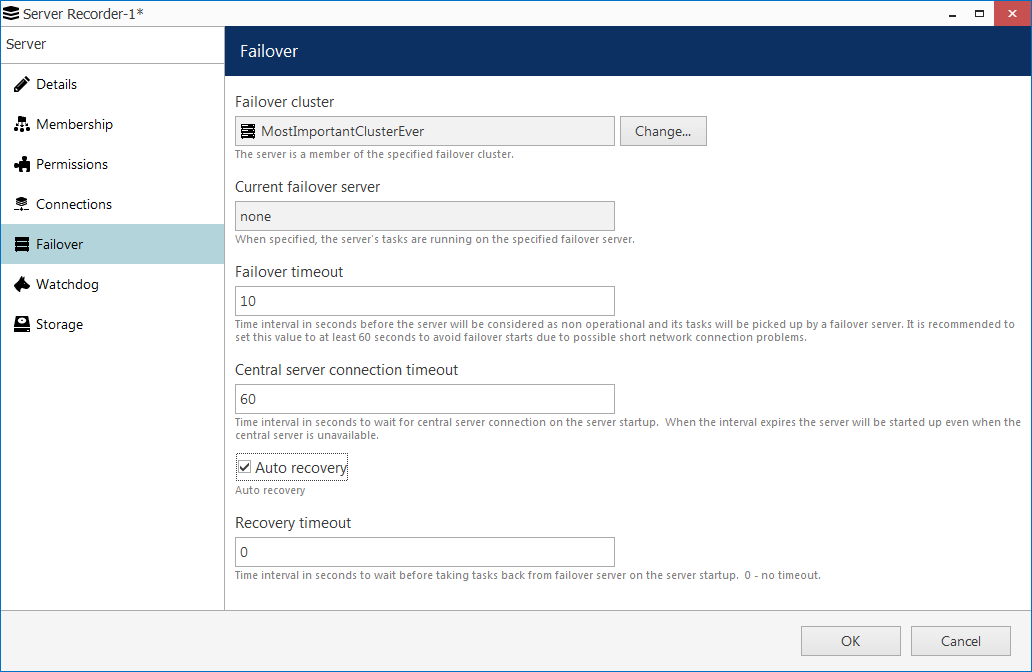
Failover settings for a primary recording server
In the Current failover server field, it should be saying none at this point: here, the currently active failover node is shown, so this field will become non-empty once the target recording server fails and is replaced by a failover server.
The rest of the settings explained:
- Failover timeout: for how long the Global server will wait after the last heartbeat message before it marks the target server faulty and replaces it with a failover node. We shall set this to the minimum equal to ten seconds;
- Central server connection timeout: defines for how long the remote server should try receiving configuration from the Global server before giving up and starting with last good known configuration. Also set to minimum, one minute;
- Auto recovery: if enabled. the remote recording server will start operating automatically once it is back to life. If the central server connection is available at that point, the failover server will be stopped by the Global server. We need to enable this in order to ensure autonomous system operation (otherwise, the failover will continue operating until manually replaced by the primary server);
- Recovery timeout: delay before Global server activates the target server once it is back online; we shall set this to zero to make the recovered server resume operation without delay.
Repeat this for every primary recording server in the list.
Setting Up Failover Nodes
For failover servers, the settings differ a bit. Double-click a server that is intended to be a failover node and stay on the Details tab: here, enable the Failover node role.
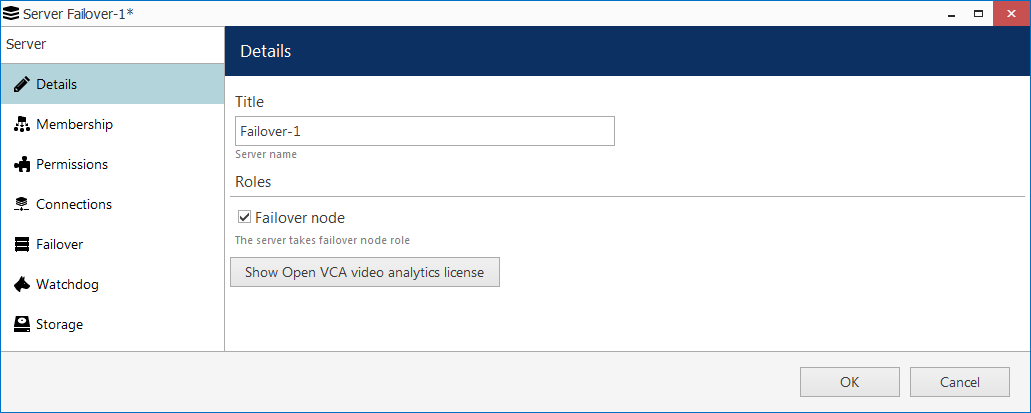
Enabling the failover node role
Next, switch to the Failover tab: note that there are fewer settings here this time as there is no need to define any auto recovery settings. The Failover timeout parameter will be used when this server fails while operating with an assigned primary server configuration so that the faulty failover server is replaced with another (next) failover node: we shall set this to ten seconds, similarly to the regular recording server. Analogously, the Central server connection timeout parameter shall be one minute.
Failover settings for a failover node
Put the failover node into the same failover cluster and save the server configuration by clicking OK.
The failover functionality is now enabled within your EVO Global system for the specified servers.
Track Server Status
Current server status and also hardware load (for connected machines) can be viewed in the Monitoring section of EVO Console, under Servers.
- If a recording server is offline and its duties are performed by a failover node, failover server status will be Substituted and its failover configuration will display the primary recording server name (whose configuration is currently used).
- At the same time, the faulty recording server will have an Unknown status and will be marked red as unavailable.
Also, for each primary recording server, its current failover substitute is displayed in the server settings, Failover tab (as shown in the snapshot above).
Intended Effect
Once you have clustered the servers and configured them as described above, EVO Global is ready for the recording server misbehavior: whenever any of the two recording servers fails, it will be replaced by a failover server right away. In addition to the camera configuration, the failover server sustains the state of the server event & action configuration.
From the point of view of the connected clients — EVO Monitor, mobile apps, and others — all failover operations are transparent for the user's convenience. Clients receive the requested live streams and recordings, and present these to their users, so the latter may not even suspect something might have gone wrong with any of the servers.
Recordings that have been made on failover servers remain there until they are erased, having reached one of the quotas. Individual archive duration quotas set for certain channels will affect all servers, i.e., the outdated recordings will be erased from the failover servers as well (provided, of course, that these servers are online and connected to the Global server).
Tips and Tricks
There are a few hints that can make your experience with EVO Global failover even more exciting :)
- You can force a recording server to be replaced by a failover node before taking it down for maintenance, in this way eliminating the downtime (those several seconds necessary to re-initialize the streams). In this case, do not forget to set the recording server's recovery timeout to be greater than zero so that you have time to turn it off! You can do this via Console > Configuration > Failover clusters > view cluster servers > Change failover server.
- Server role (failover/primary) can be assigned already at the recording server auto discovery step.
- No matter how fancy the recording servers' storage configuration is (different labels for per-disk channel grouping etc), failover servers can simply have one capacious storage with a Default label.
Now to you are ready to set this up for your own EVO Global system. May your servers never break down!


